Contents |
La arquitectura web trabaja con dos nodos:
Estos nodos son lógicos: pueden estar ubicados físicamente en la misma máquina, pero igualmente tendremos una separación de componentes en cliente y servidor.
El cliente hace pedidos a través de un puerto contra el servidor, el servidor responde. El flujo de mensajes siempre comienza en el cliente:

Antes de meternos más de lleno, nos preguntamos: la tecnología de objetos ¿es consistente con la metáfora “pedido-respuesta” (request/response)? Sí, en definitiva es la representación de lo que es un mensaje.
Lo que pasa es que en un sistema con objetos no pongo restricciones: cualquiera puede ser emisor y cualquiera receptor. En cambio en la tecnología web siempre es el cliente el que pide y siempre el servidor el que responde.
El cliente dice: “necesito x”. Esto se traduce en una dirección de una página en particular, esa dirección recibe el nombre de URL (Uniforme Resource Locator, o forma de encontrar un recurso en el servidor):
http://localhost:8080/html-css/index.html
donde
localhost es el web server que está en la PC local, que equivale a la dirección IP 127.0.0.1La forma en que publicaremos las páginas como rutas depende de la tecnología en la que trabajemos y lo veremos más adelante, lo importante es entender que una página html es accesible para un usuario con una ruta única llamada URL.
Http es un protocolo no orientado a conexión que define la forma de comunicación entre el cliente y el servidor.
Recordemos que no-orientado a conexión significa que no guarda ninguna información sobre conexiones anteriores, por lo que no tenemos el concepto de sesión de usuario, es un protocolo sin estado (stateless protocol). Esto tiene varias implicancias, la más fuerte es que requiere que la aplicación mantenga la información necesaria para mantener una sesión (por ejemplo, sabiendo qué usuario es el que está haciendo una operación).
Un mensaje http tiene formato de texto, por lo que es legible al usuario y fácilmente depurable, como vemos en el siguiente video:
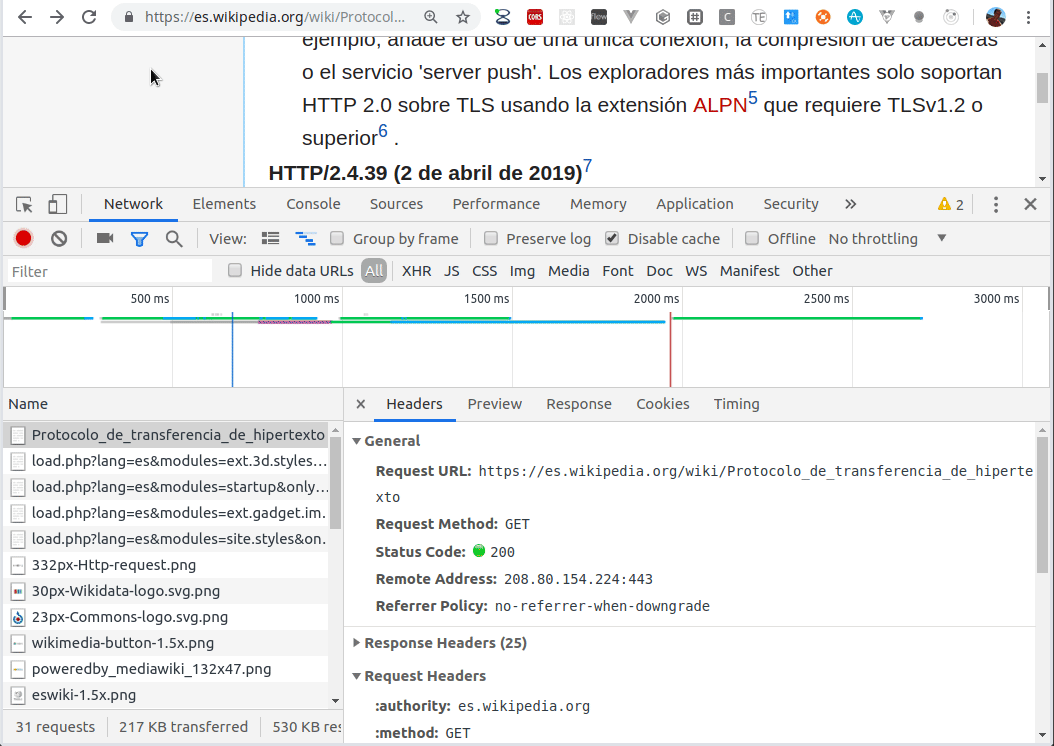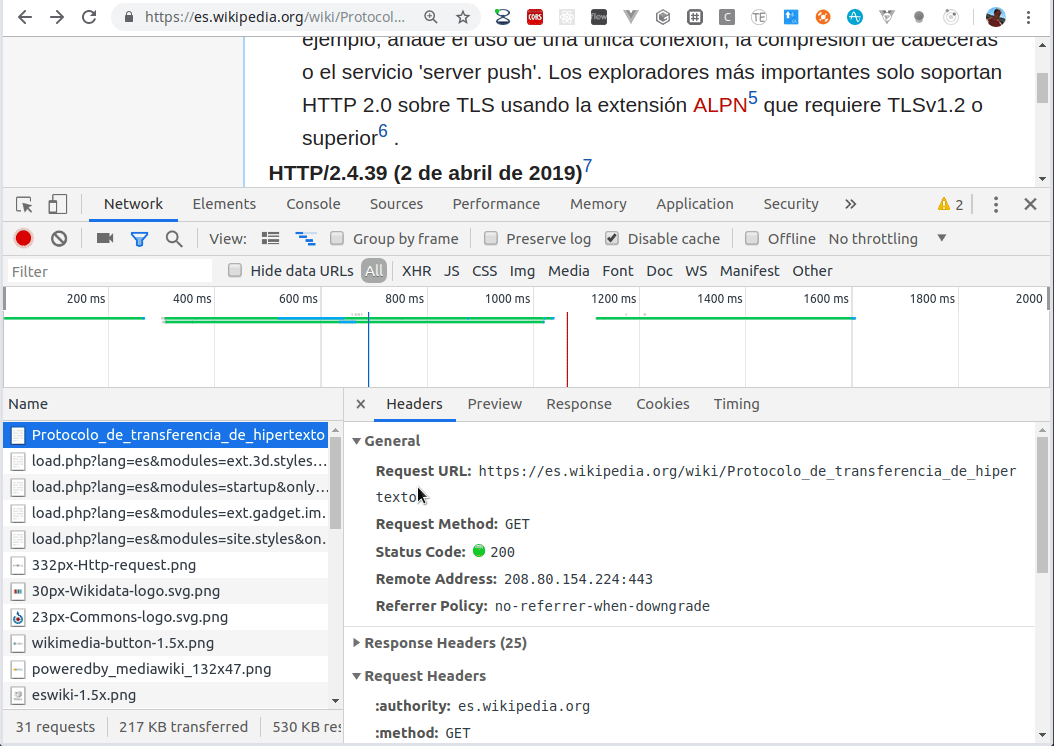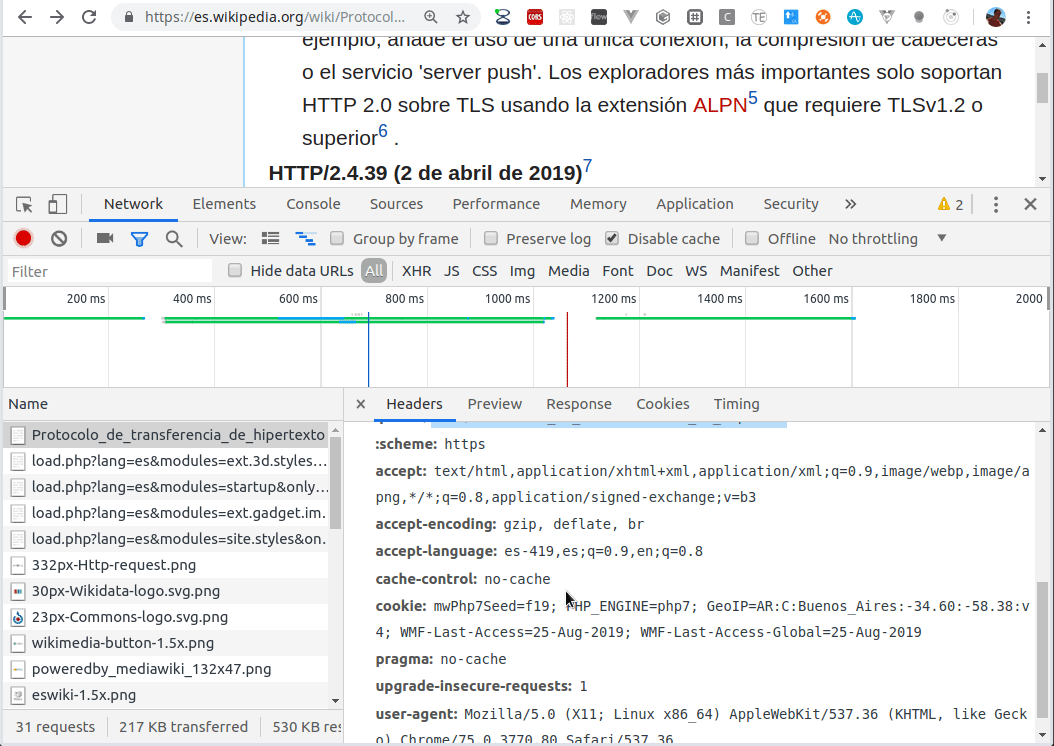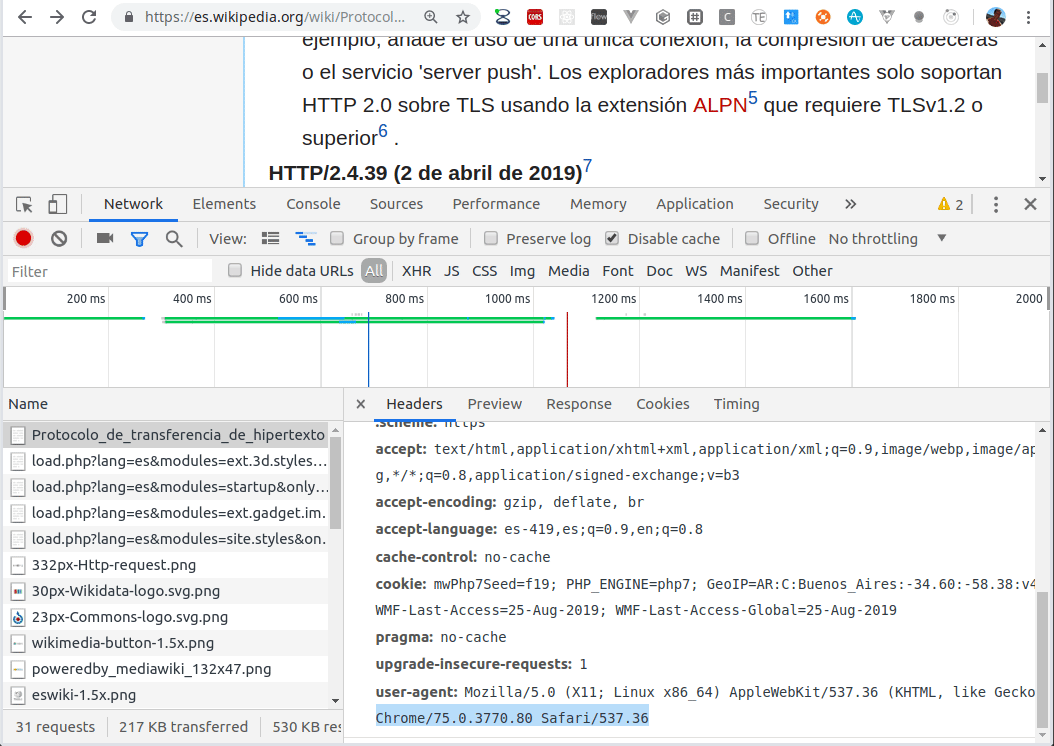
Abrimos en un navegador las herramientas de desarrollo (por lo general es la tecla F12), y en la solapa Network podemos inspeccionar las distintas respuestas que procesa el navegador, con el pedido http original que hace un mensaje de tipo GET.
Un cliente puede enviar un pedido al servidor utilizando diferentes métodos
GET: asociada a una operación de lectura, sin ningún otro efectoHEAD: es exactamente igual al pedido vía GET pero enviando únicamente el resultado de la operación en un header, sin el contenido o bodyPOST: se suele asociar a una operación que tiene efecto colateral, no repetiblePUT: está pensado para agregar información o modificar una entidad existenteDELETE: se asocia con la posibilidad de eliminar un recurso existenteOPTIONS: permite ver todos los métodos que soporta un determinado servidor webTRACE: permite hacer el seguimiento y depuración de un mensaje http (se agrega información de debug)CONNECT: equivalente a un ping, permite saber si se tiene acceso a un hostMás adelante volveremos sobre esto al estudiar REST. Ahora veremos la diferencia entre hacer un pedido mediante GET vs. POST.
Aquí los parámetros viajan dentro de la URL como par clave=valor:
http://www.appdomain.com/users?size=20&page=5
? delimita el primer parámetro& delimita los siguientes parámetrosLa ventaja de utilizar este método es que dado que http es un protocolo no orientado a conexión, podemos reconstruir todo el estado que necesita la página a partir de sus parámetros (es fácil navegar hacia atrás o adelante). Por otra parte es el método sugerido para operaciones sin efecto, que recuperan datos de un recurso.
Por otra parte, no es conveniente para pasar información sensible (como password o ciertos identificadores), algunos navegadores imponen un límite máximo de caracteres para estos pedidos y necesita codificar los caracteres especiales (p. ej. el espacio a %20) dado que el request solamente trabaja con el conjunto de caracteres ASCII.
Los parámetros viajan en el BODY del mensaje HTML, no se ven en la URL del browser. Aquí no hay restricciones de tamaño para pasaje de información y tampoco se visualizan los parámetros en la URL del browser.
La recomendación W3C (World Wide Web Consortium) dice que deberíamos usar
el servidor responde a ese pedido: esa respuesta es una nueva página con un código de estado HTTP:
El lector puede buscar la lista de códigos de error HTTP (las especificaciones RFC 2616 y RFC 4918) y formas de resolverlos.
La página es la mínima unidad de información entre cliente y servidor, lo que implica:
String oriented programming: la comunicación entre cliente y servidor involucra solo texto, necesitamos adaptar fechas, números, booleanos y también los objetos de negocio (socios de un videoclub, alumnos, materias, vehículos de una flota, etc.) así como las colecciones.
El servidor contesta con un string que tiene
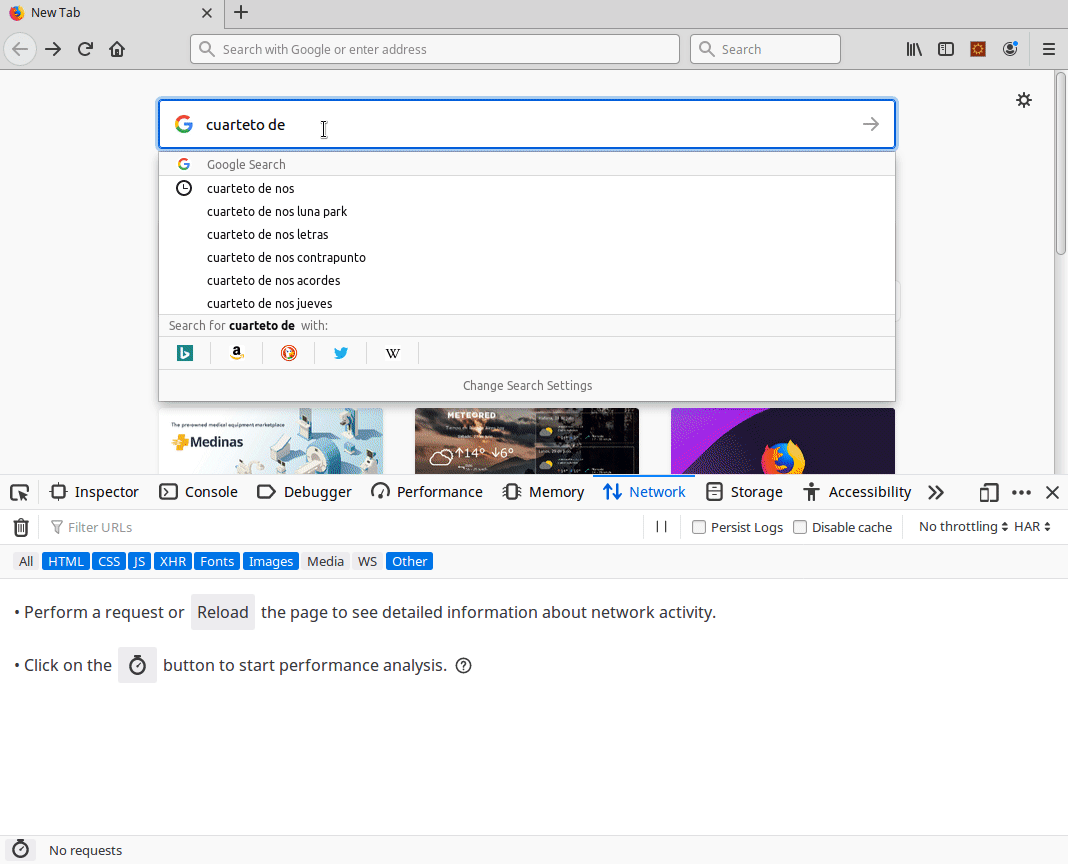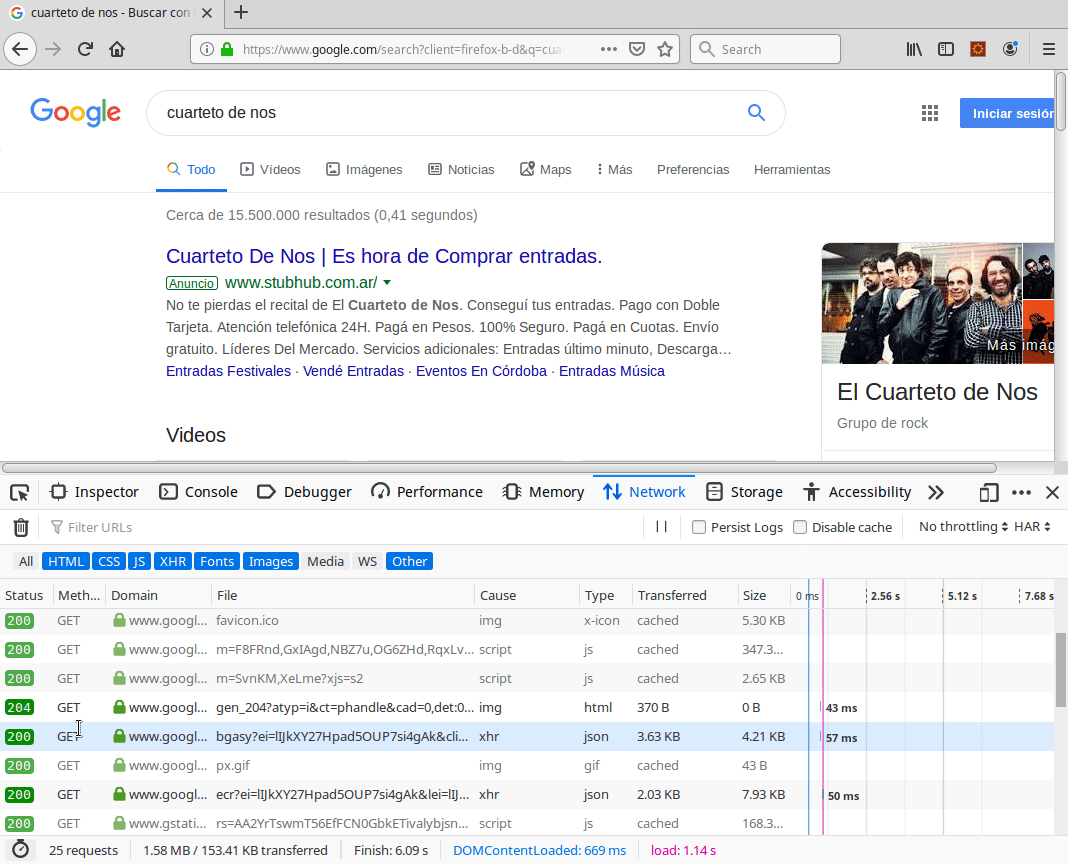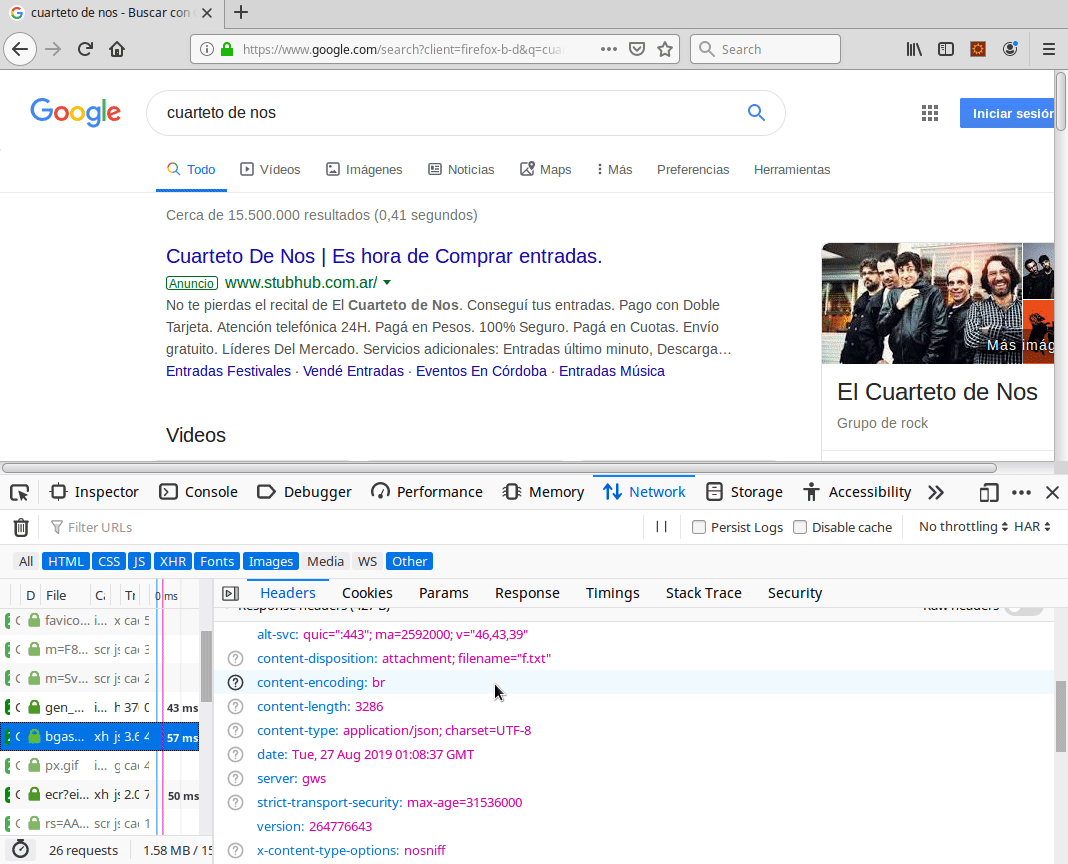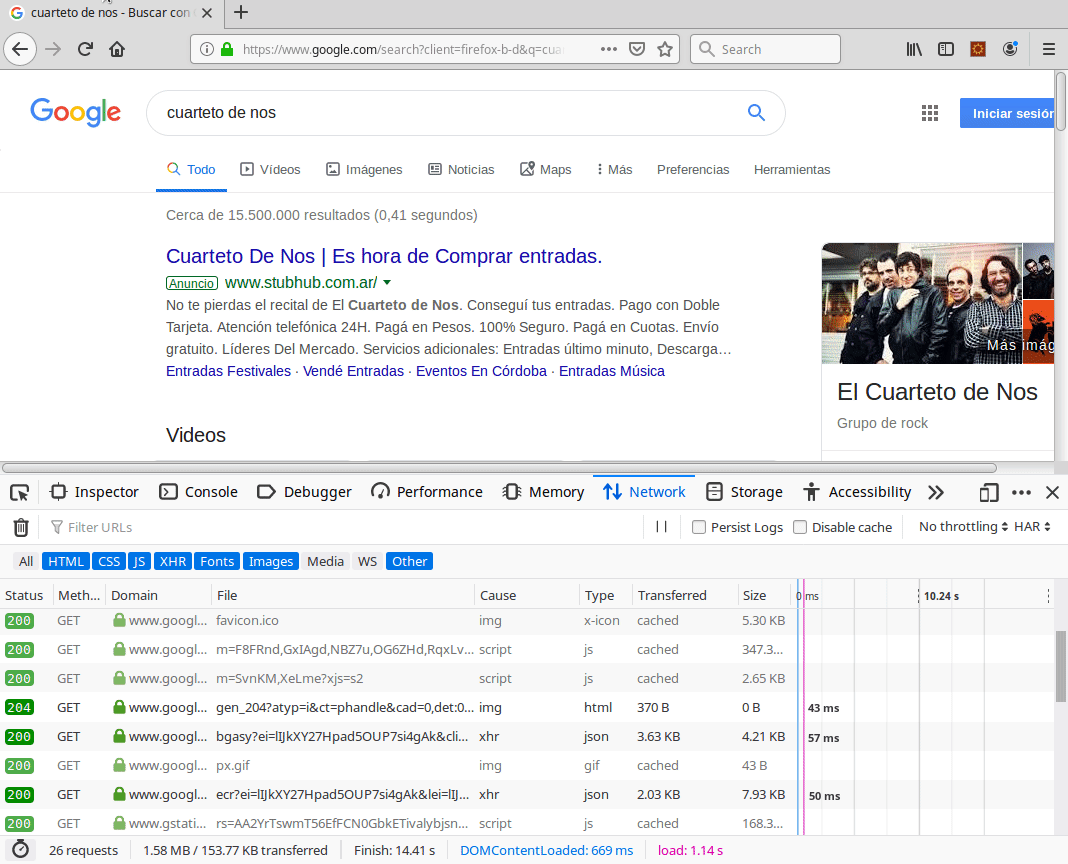
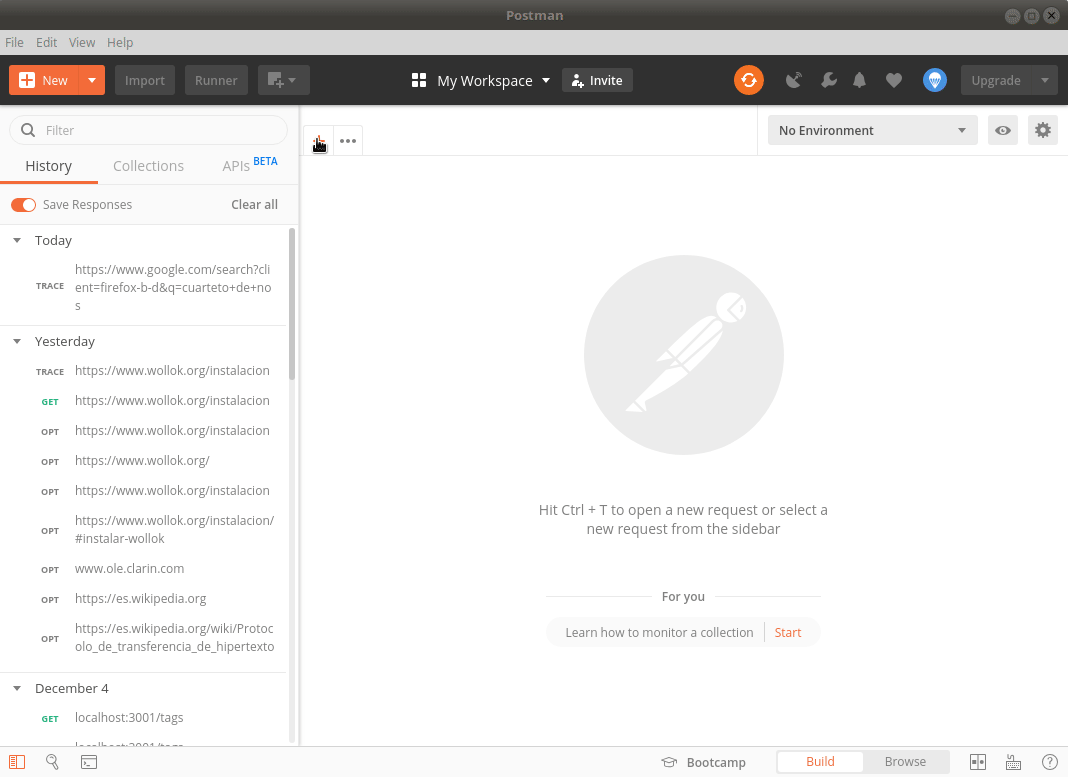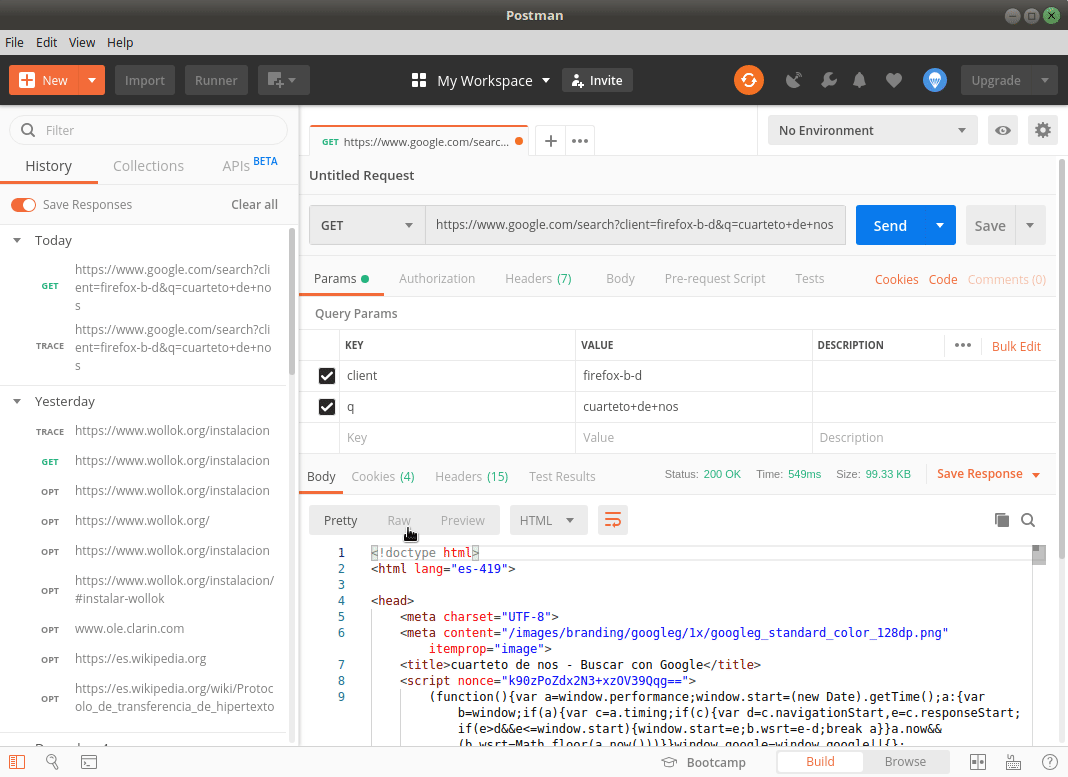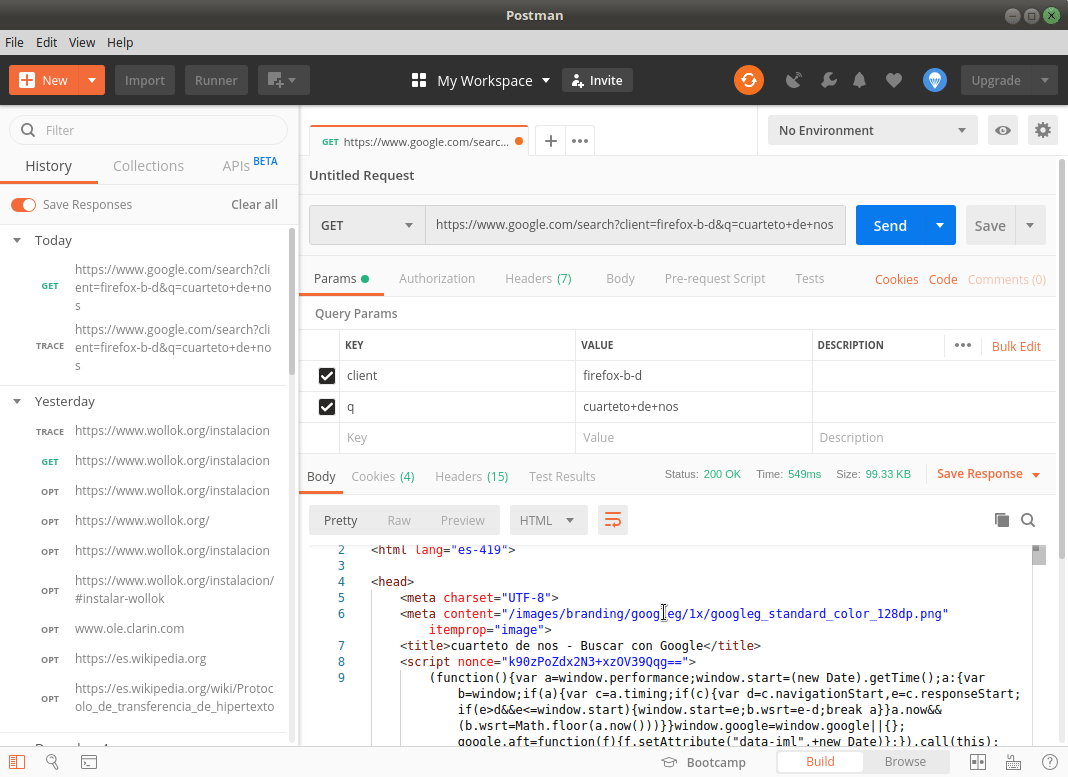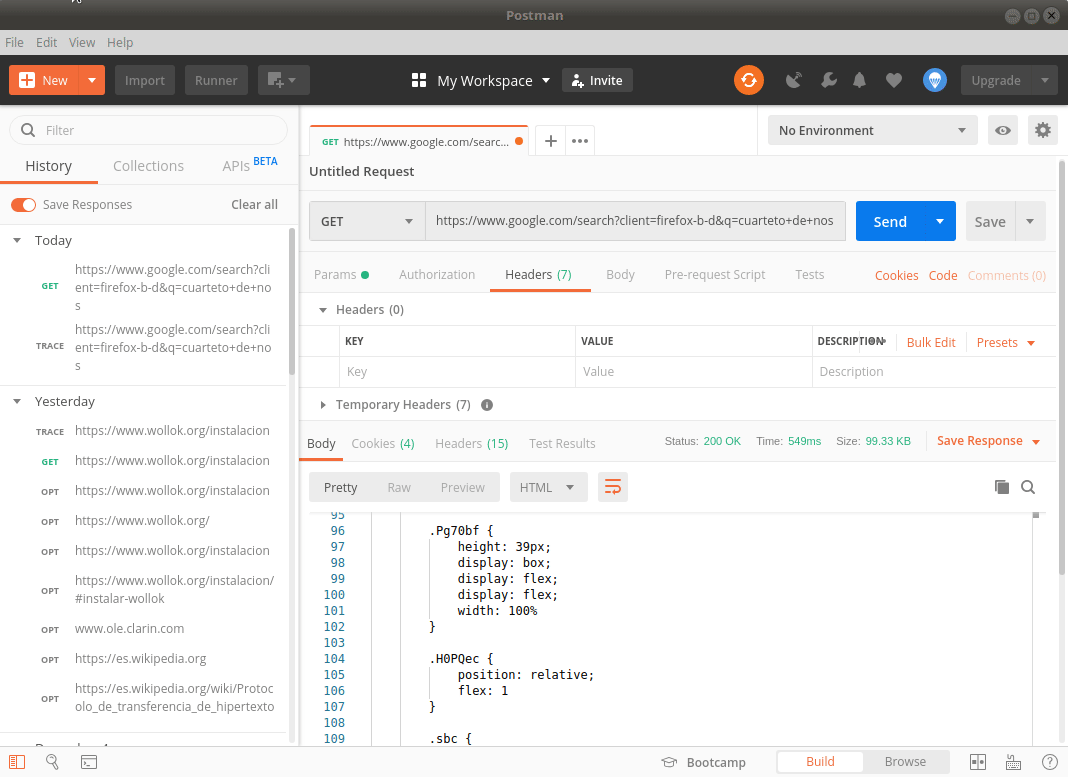
Arriba vemos la respuesta del navegador al buscar “Cuarteto de Nos” y abajo cómo procesa la consulta el cliente Postman.
 Home
Home Artículos
Artículos
