Concepto de cliente y servidor
Una aplicación puede pensarse desde la óptica del
- cliente: el que realiza pedidos
- servidor: el que responde a esos pedidos
La separación puede ser:
- lógica: ambos componentes residen en la misma máquina
- lógica y física: además de pensarse como componentes separados el usuario utiliza un cliente en su máquina y accede al servidor que concentra esos pedidos y se encarga de responderlos.
¿Qué tipo de pedidos hace el cliente? Esto depende de la arquitectura sobre la cual trabajemos:
Arquitectura de las UI
- Aplicación centralizada
- Aplicación distribuida (Cliente/Servidor)
Aplicación centralizada
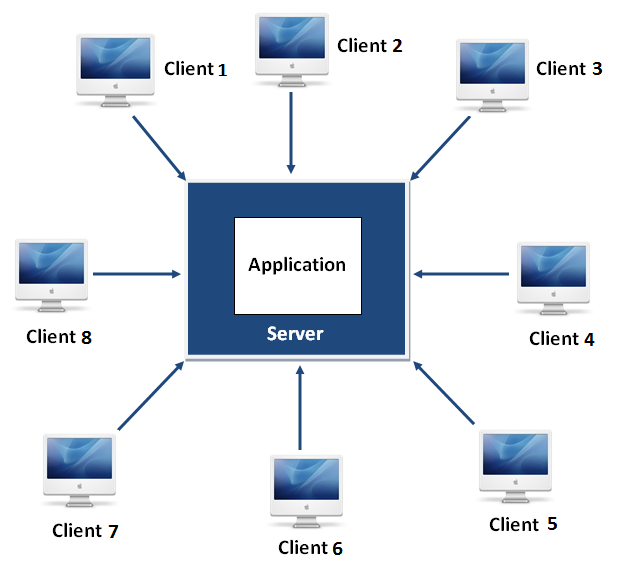
El cliente tiene poca o nula inteligencia. El servidor tiene muchas responsabilidades, esto es:
- recibe los parámetros del cliente, los valida y los transforma
- procesa las acciones de negocio
- transforma los resultados de esas acciones y
- genera la visualización que va a obtener el cliente como respuesta.
Del lado del cliente casi no hay lógica, ni de presentación ni de negocio, es una “terminal boba”. Es el modelo que siguen las arquitecturas mainframe y la web en sus orígenes, donde el browser solo tenía capacidades de mostrar la información y los controles que el servidor le enviaba.
Cliente / Servidor - Aplicaciones distribuidas
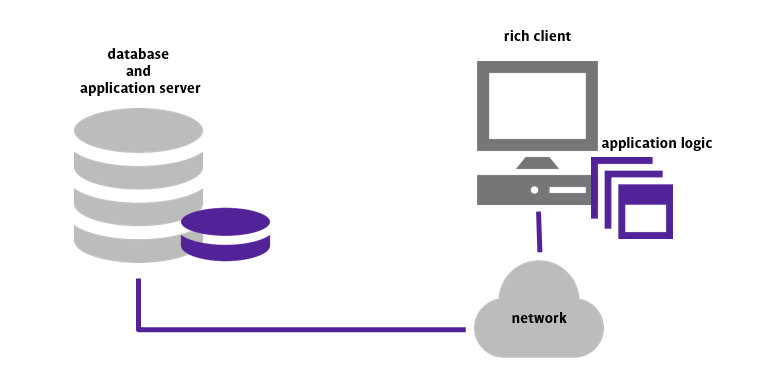
En este tipo de aplicaciones, se asume que
- los clientes tienen más capacidad de procesamiento, por lo tanto suelen presentar una interfaz de usuario más “rica” que las aplicaciones centralizadas (por eso también se las suele llamar RIA o Rich Internet Applications)
- la comunicación hacia el servidor suele ser un cuello de botella, así que se trata de minimizar la cantidad de información a pasar entre cliente y servidor. Por lo general el cliente hace un pedido, la consulta se procesa en el servidor y vuelve la información procesada para que el cliente la presente en un formato amigable.
- las aplicaciones distribuidas son más complejas arquitecturalmente: se dividen en 2, 3 hasta n niveles
Peer to Peer
Otra alternativa consiste en la red peer-to-peer (P2P), donde cada equipo actúa como cliente o servidor dependiendo de si hace un pedido o lo responde (consumer/producer). No existe el servidor como equipo de sincronización, sino que cada equipo mantiene su propio estado:
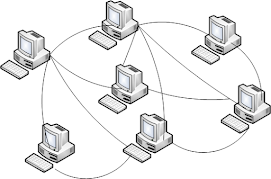
Ejemplos de aplicaciones peer to peer son Skype, eMule, μTorrent, entre otras.
Análisis comparativo P2P vs. C/S
Ventajas de la visión Cliente/Servidor
- Centralización del control: los accesos, recursos y la integridad de los datos son controlados por el servidor de forma que un programa cliente defectuoso o no autorizado no pueda dañar el sistema. Esta centralización también facilita la tarea de poner al día datos u otros recursos (mejor que en las redes P2P).
- Escalabilidad: se puede aumentar la capacidad de clientes y servidores por separado. Cualquier elemento puede ser aumentado (o mejorado) en cualquier momento, o se pueden añadir nuevos nodos a la red (clientes y/o servidores).
- Dado que hay una cierta independencia entre clientes y servidores, es posible reemplazar, reparar, actualizar o trasladar alguno de ellos con un bajo impacto, siempre y cuando ciertas variables se mantengan estables (debe estar un servidor activo, hay que asegurar el enlace entre los nodos, etc.)
- Hay muchas más tecnologías desarrolladas para el paradigma de C/S.
Ventajas de la visión Peer to Peer
- La congestión del tráfico ha sido siempre un problema en el paradigma de C/S. Cuando una gran cantidad de clientes envían peticiones simultaneas al mismo servidor, puede ser que cause muchos problemas para éste (a mayor número de clientes, más problemas para el servidor). Al contrario, en las redes P2P como cada nodo en la red hace también de servidor, cuanto más nodos hay, mejor es el ancho de banda que se tiene.
- El paradigma de C/S clásico no tiene la robustez de una red P2P. Cuando un servidor está caído, las peticiones de los clientes no pueden ser satisfechas. En la mayor parte de redes P2P, los recursos están generalmente distribuidos en varios nodos de la red. Aunque algunos salgan o abandonen la descarga; otros pueden todavía acabar de descargar consiguiendo datos del resto de los nodos en la red.
- El software y el hardware de un servidor son generalmente muy determinantes: se necesita un buen “fierro” para que un servidor de soporte a una gran cantidad de clientes.
- El cliente no dispone de los recursos que puedan existir en el servidor y viceversa. Por ejemplo, una aplicación que ejecuta en el servidor no puede escribir en el disco local del cliente.
Interfaces orientadas a caracter y gráficas
- Orientadas a caracter: las consolas de configuración de routers, o las consolas de administración de herramientas como git, Maven o Travis, el intérprete de comandos de los sistemas operativos, el sistema de reserva de vuelos que trabaja con comandos específicos vs.
- las interfaces gráficas: las que vamos a trabajar mayoritariamente a lo largo de la materia.
¿Qué características tienen las interfaces orientadas a caracter?
- son menos intuitivas, requiere memorizar comandos y códigos internos
- por esto se tarda más en aprender las operaciones que con las interfaces gráficas
- una vez pasada la curva de aprendizaje los usuarios expertos trabajan mucho más velozmente que en la modalidad gráfica
Links relacionados
 Home
Home Artículos
Artículos
